Enterprise LangChain Development Services in Chennai
Move beyond basic chatbots. We use LangChain to orchestrate Large Language Models (LLMs), build custom AI agents, and deploy Retrieval-Augmented Generation (RAG) systems that interact securely with your enterprise data.
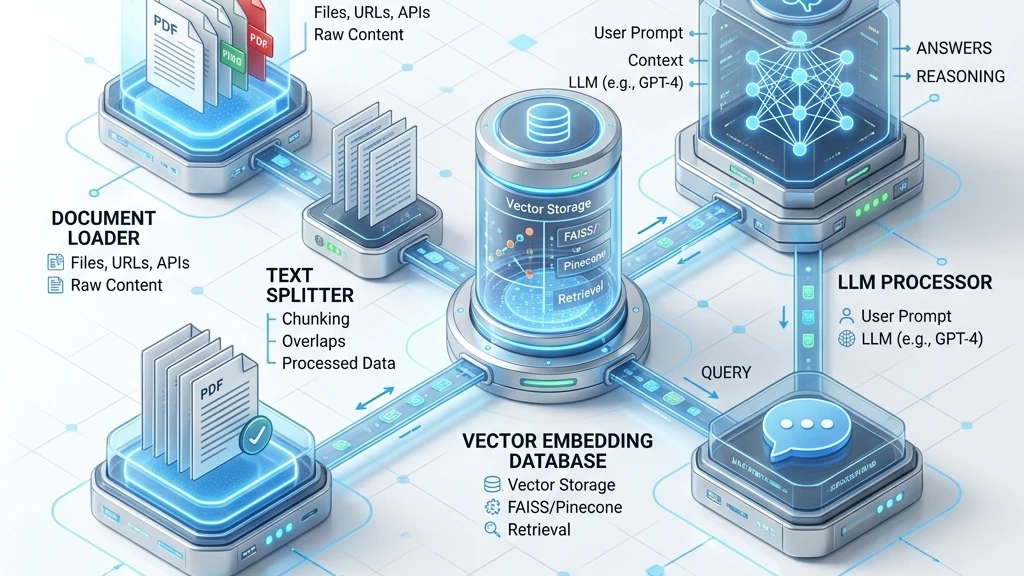
Context-Aware Generative AI Orchestration
Standard ChatGPT wrappers lack the context required to make business decisions. LangChain is the industry-standard orchestration framework that bridges this gap, allowing LLMs to execute complex chains of thought and interact directly with your proprietary data. At OrcaMinds, we build advanced GenAI applications that securely query your databases, APIs, and document repositories.
Our AI engineering team specializes in Retrieval-Augmented Generation (RAG), semantic vector search integration (Pinecone, ChromaDB), and autonomous AI Agent development. We transform passive AI models into active enterprise tools that summarize legal contracts, execute database queries via SQL agents, and autonomously resolve customer support tickets.
Why Manual Business Processes Stifle Growth
In today's competitive landscape, relying on manual data migration, copy-pasting, and email routing limits your ability to scale operations.
- High Operational Overhead: Employees spend valuable hours manually syncing spreadsheets, CRM records, and chat notifications.
- Frequent Administrative Errors: Manual data transfers lead to invoice billing anomalies, typos, and delayed communications.
- Slow Execution Times: Orders, leads, or support tickets wait in queues for hours waiting for manual approvals or assignment.
The Solution: Automated workflows trigger actions instantly across your apps (n8n/Zapier) in milliseconds with 100% data consistency.
The Limitations of Off-The-Shelf LLMs
Out-of-the-box LLMs suffer from "hallucinations" and possess zero knowledge of your company's internal data, making them unreliable for enterprise use. Furthermore, foundation models are restricted by limited context windows, meaning they cannot read a 10,000-page internal knowledge base to answer a single question accurately.
Enterprises need a secure orchestration layer that acts as the "brain," retrieving only highly relevant proprietary data chunks, injecting them into a prompt template, and forcing the LLM to ground its answers strictly in factual enterprise data.
Our LangChain Development Capabilities
RAG System Implementation
Eliminate AI hallucinations. We build RAG architectures that convert internal documents into vector embeddings for accurate, data-grounded AI answers.
Autonomous AI Agents
Develop task-oriented agents equipped with custom "Tools" allowing them to browse the web, run Python code, or make REST API calls to your SaaS stack.
Advanced Memory Management
Implement intelligent memory buffers (ConversationSummaryBuffer) to maintain long-term context across lengthy user interactions without exceeding token limits.
Text-to-SQL Agents
Empower non-technical staff to query complex enterprise databases securely using natural language, translating questions directly into optimized SQL.
Dynamic Prompt Engineering
We build robust LangChain prompt templates that dynamically inject structured output parsers, forcing the LLM to return strict JSON arrays.
Local LLM Deployment
For high-security requirements, we orchestrate LangChain with open-source models (Llama 3, Mistral) running entirely within your VPC.
Our LangChain Architecture Process
Data Ingestion & Chunking Strategy
We extract your data from PDFs, Notion, or S3, utilizing advanced text splitters to chunk the data optimally for semantic retrieval.
Embedding & Vector Database Setup
We convert the chunks into dense vector representations and store them in highly scalable vector databases like Pinecone, Milvus, or pgvector.
Chain / Agent Orchestration
We write the Python logic to link the LLM, the retriever, and the memory systems, designing specialized Tools for the agent to execute actions.
Evaluation & Prompt Refinement
We utilize evaluation frameworks (like LangSmith) to audit the agent's accuracy, refining prompts to eliminate hallucinations before production deployment.
LangChain Solutions in Production
See how we use LangChain to build intelligent workflows that solve complex, data-heavy enterprise problems.
1. Internal Technical Documentation RAG
Engineering & IT
Challenge: New developers spend weeks navigating thousands of pages of disorganized Confluence and GitHub documentation.
Our Approach: Built a LangChain RAG pipeline that vectorized the entire documentation repository into Pinecone. Developers ask questions via a Slack bot, and the LLM retrieves the specific code snippets and explains them.
Projected Impact: Developer onboarding time decreased by 30%, and search time was virtually eliminated.
2. Text-to-SQL Analytics Agent
Data & BI Teams
Challenge: Business managers constantly block data engineers with ad-hoc requests to pull sales figures from complex PostgreSQL databases.
Our Approach: Deployed an SQL Agent using LangChain. The agent intercepts natural language questions (e.g., "What were Q3 sales in Europe?"), writes the corresponding SQL query, executes it safely (read-only), and returns a formatted summary.
Projected Impact: Instant analytics access for non-technical staff, saving the data team 15 hours per week.
3. Legal Contract Comparison Tool
Legal Firms
Challenge: Paralegals spend days manually comparing incoming vendor agreements against the company's standard Master Service Agreement (MSA).
Our Approach: Utilized LangChain's Map-Reduce chain to summarize and extract specific liability clauses from both documents, flagging risky deviations in a structured JSON output.
Projected Impact: Initial contract review time slashed from 4 hours to under 5 minutes.
4. Autonomous Email Support Agent
E-Commerce Customer Service
Challenge: Human agents were overwhelmed answering basic "Where is my order?" emails during peak holiday seasons.
Our Approach: Engineered a LangChain Agent equipped with "Tools" to access the Shopify API. The agent reads the email intent, fetches real-time shipping data, drafts a personalized reply, and sends it—without human intervention.
Projected Impact: Successfully deflected 60% of tier-1 support tickets automatically.