LLM Development Services in Andhra Pradesh
Build custom Large Language Models tailored to your business. Fine-tuning, prompt engineering, deployment, and integration of state-of-the-art LLMs.
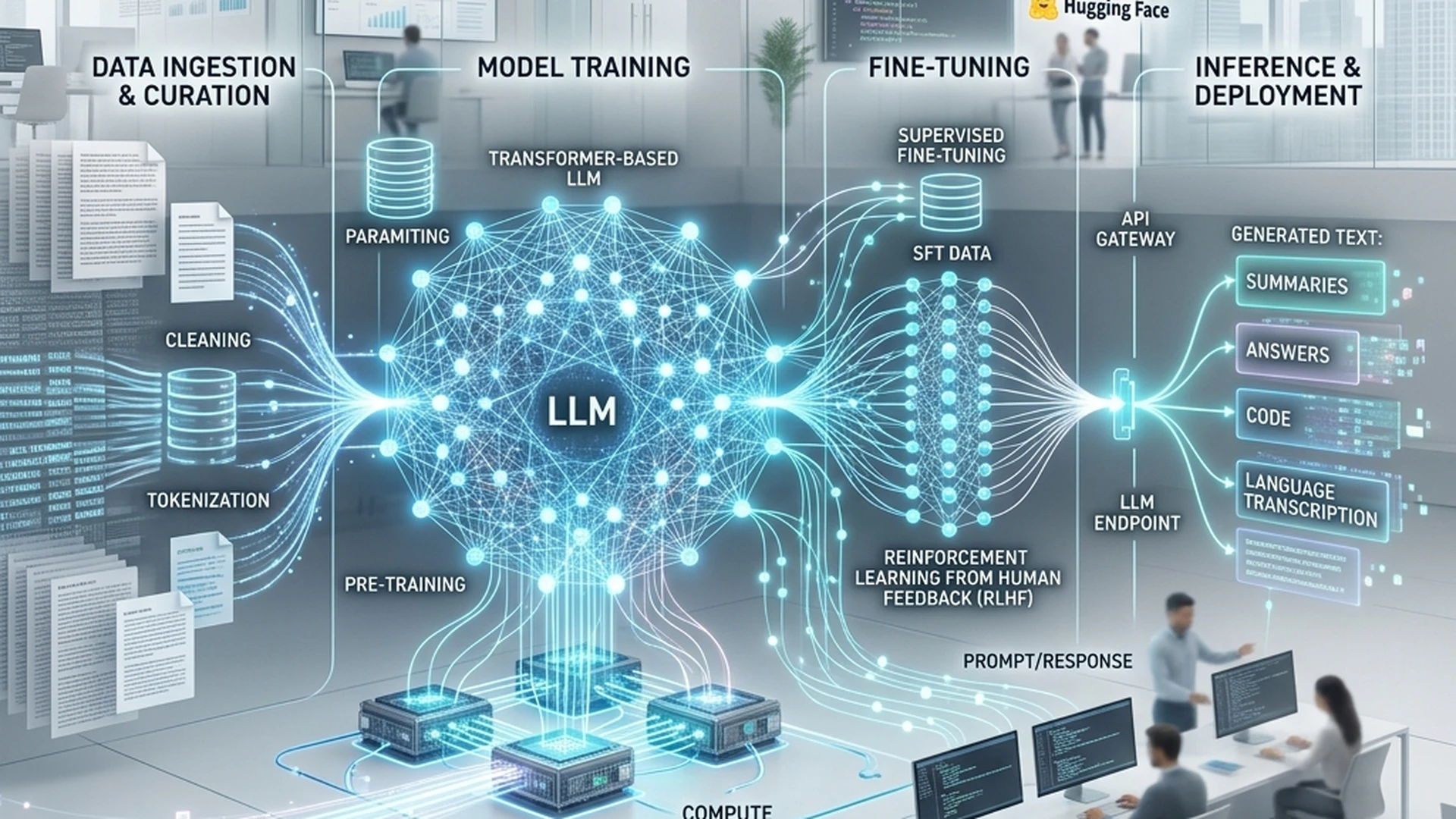
Custom Large Language Models for Your Business
Large Language Models (LLMs) are transforming how businesses interact with data and customers. At OrcaMinds, we help you harness the power of LLMs through custom fine-tuning, prompt engineering, and seamless deployment. Our expertise spans GPT-4, LLaMA, Claude, Gemini, and open-source models like Llama 3, Mistral, and Falcon.
We build LLM solutions for content generation, code assistance, document analysis, customer support, and knowledge management. Whether you need to fine-tune a model on your proprietary data, optimize prompts for specific tasks, or deploy LLMs at scale, our team delivers production-ready solutions.
Why Off-the-Shelf LLMs Aren't Enough for Enterprises
Using public AI chatbots like standard ChatGPT or Claude is great for everyday tasks, but relying on them for critical business operations introduces severe risks and limitations.
- Data Privacy & Security Risks: Sending proprietary company data or customer PII to public APIs can violate compliance (GDPR, HIPAA) and leak trade secrets.
- Lack of Domain Knowledge: Generic models do not know your company's internal documentation, specific product features, or unique brand voice.
- AI Hallucinations: Without proper constraints, fine-tuning, or RAG architecture, generic LLMs confidently generate false or misleading information.
The Solution: Custom-deployed LLMs with RAG (Retrieval-Augmented Generation) keep your data 100% private and ensure answers are strictly based on your verified documents.
Our LLM Capabilities
Custom Fine-Tuning
Fine-tune pre-trained LLMs on your proprietary data to improve accuracy, relevance, and domain-specific knowledge.
Prompt Engineering
Design and optimize prompts to get the most accurate, relevant, and consistent responses from LLMs.
Model Deployment
Deploy LLMs on cloud (AWS, Azure, GCP) or on-premises with scalable APIs for production use.
RAG Integration
Combine LLMs with your knowledge base using Retrieval-Augmented Generation for accurate, context-aware responses.
LLM Evaluation & Monitoring
Continuous evaluation of model performance, hallucination detection, and response quality monitoring.
Cost Optimization
Optimize token usage, caching strategies, and model selection to reduce operational costs.
LLM Models We Work With
GPT-4
Claude 3
Gemini
LLaMA 3
Mistral
Falcon
Our LLM Development Process
Requirements & Use Case Analysis
We identify your specific LLM use cases, data requirements, and success metrics.
Model Selection & Fine-Tuning
We select the optimal base model and fine-tune it on your proprietary data for maximum accuracy.
Integration & Deployment
We deploy your custom LLM via APIs, chat interfaces, or integrate into existing applications.
Monitoring & Optimization
Continuous monitoring, performance optimization, and regular model updates.
High-Impact Use Cases & Projected ROI
Explore how our custom LLM architectures solve complex enterprise challenges and deliver measurable business value.
1. Enterprise Knowledge Retrieval (RAG)
Corporate IT & HR
Challenge: Employees spend 20% of their day searching through scattered PDFs, internal wikis, and SharePoints for company policies.
Our Approach: Building an internal LLM portal using Retrieval-Augmented Generation (RAG) to instantly answer employee questions with exact citations from company documents.
Projected ROI: Saves an average of 1.5 hours per employee per day in information retrieval.
2. Automated Legal Contract Drafting
Legal & Real Estate
Challenge: Paralegals and attorneys spend hours drafting routine NDAs, lease agreements, and compliance documents.
Our Approach: Fine-tuning LLaMA 3 exclusively on a firm's historical contracts to generate highly accurate, jurisdiction-specific legal drafts from simple prompts.
Projected ROI: 75% reduction in drafting time, allowing firms to handle 3x more clients without new hires.
3. Specialized Code Co-Pilots
Software & Tech
Challenge: New developers take months to learn massive legacy codebases and proprietary frameworks, slowing down product releases.
Our Approach: Deploying a secure, locally-hosted LLM (like CodeLlama) trained on your company's private GitHub repositories to suggest code and explain legacy architecture.
Projected ROI: Developer onboarding time reduced by 50%, with a 20% increase in daily commit volume.
4. Hyper-Personalized Marketing Copy Engine
E-Commerce & Retail
Challenge: Creating thousands of unique product descriptions and targeted email campaigns requires massive agency budgets.
Our Approach: Integrating GPT-4 APIs with dynamic prompt engineering to automatically generate SEO-optimized product descriptions directly from vendor spec sheets.
Projected ROI: Content creation costs slashed by 80%, allowing for daily catalog updates.